Machine Learning
Ici, vous trouverez un "journal de bord" des principales étapes de la création de mon modèle de Machine Learning. (Cette page me servira de mémento aussi).
D'abord, j'ai créé une nouvelle branche sur GitHub intitulée "V3-ML". Cette branche aura moins d'interface et sera moins "user-friendly" que les autres versions. Cela se déroulera principalement dans la console où l'utilisateur aura le choix de comment remplir ses données. Il pourra choisir l'espérance et la variance de ses attributs. Il pourra aussi choisir le nombre de fois que toutes les simulations vont se répéter pour des données plus solides. Une fois cela fait, le modèle de ML lui dira quels sont les gènes les plus importants dans une simulation pauvre, une simulation équilibrée et une simulation riche (qui seront déjà définies). Le modèle sera capable de prédire sur ces données un échantillon de Minos qui sont susceptibles de survivre le plus longtemps. Enfin, l'utilisateur aura la possibilité de regarder X simulations où les Minos susceptibles de survivre auront un marquage.
Documentation
Pour cet apprentissage, j'ai utilisé les cours de François Husson, enseignant chercheur en statistiques. - https://www.youtube.com/watch?v=CCzGRyO2CTc
Plan d'action
Après des recherches, j'ai trouvé que le modèle de ML qui conviendrait à mon projet et pas trop difficile à prendre en main est le modèle de régression linéaire multiple. Ici, pas de réseaux de neurones difficiles, on commence par les bases.
1. Préparation et normalisation
A la différence des rendu visuels, ici on essaie d'utiliser uniquement les donnnées parlantes. Je garde donc uniquement le génome et le temps de survie des Minos. Je me suis rendu compte que ces données n'étaient pas normalisées. J'ai donc décider de les borner entre 0 et 1 mais c'était difficile car je ne pouvais pas connaitre le maximum ni le minimum à chaque simulation. J'ai donc fais le choix de les normaliser selon un écart à la moyenne (\(\mu\) que je connais) avec la formule \(z = \frac{x - \mu}{\sigma}\)
Notes de cours
Vous trouverez ici les notes que j'ai prise du cours de François Husson. Tout ce qui est écrit ici est compris et maitrisé.
Ici, l'objectif est d'expliquer quels gènes ont un rôle important et de prédire le temps de vie d'un Minos en fonction de ses gènes.
- "Expliquer une variable quantitative Y en fonction de p variables quantitatives \(x_1, \ldots, x_p\)"
- "Prédire de nouvelles valeurs pour Y"
Formule régression simple
Pour tout \(i\) de \(1\) à \(n\) :
avec \(\varepsilon_i\) iid, \(\mathbb{E}(\varepsilon_i) = 0\), \(\mathbb{V}(\varepsilon_i) = \sigma^2\)
\(\varepsilon_i\) correspond à :
- erreur de mesure
- erreur d'échantillonnage
- facteur mal contrôlé (une valeur de x mal mesurée)
- oubli de facteur
Solution : introduction de variables supplémentaires pour réduire cette variabilité résiduelle (mieux expliquer Y)
Définition du modèle de régression multiple
Expliquer une variable réponse Y en fonction de p variables explicatives \(x_1, x_2, \ldots, x_p\)
Pour tout \(i\) de \(1\) à \(n\) :
avec \(\varepsilon_i\) iid, \(\mathbb{E}(\varepsilon_i) = 0\), \(\mathbb{V}(\varepsilon_i) = \sigma^2\)
Ici, les xi sont nos variables observées : resistance, vitesse, satiété etc... Y représente le temps de vie du Minos
Le modèle traduit l'influence de chaque variable sur Y :
- Linéarité du modèle : linéarité par rapport aux paramètres
- Additivité : les effets des variables s'additionnent
- Modèle polynomial possible : \(Y_i = \beta_0 + \beta_1 x_{i1} + \beta_2 x_i^2 + \varepsilon_i\) (important pour ne pas étudier que les effets linéaires)
Système matriciel
Notation matricielle
La réalité (Y) est égale à la prédiction (X\(\beta\)) PLUS un aléa qui n'est pas maîtrisable (\(\varepsilon\)). Cet epsilon représente à la fois une erreur du modèle (mauvais Beta) et une erreur du monde (le minos a eu de la chance)
L'objectif est donc d'estimer tous les coefficients \(\beta_i\) (le vecteur \(\beta\)).
Estimation des paramètres du modèle
Pour estimer les paramètres \(\beta\), on va chercher à minimiser l'écart entre une observation et la prévision par le modèle (le tout au carré) :
Minimiser la norme en Y et X\(\beta\). Il est possible de trouver les \(\beta\) en minimisant cette quantité (dériver cette fonction et annuler la dérivée).
Explication visuelle :
On a le nuage de point (les minos), il faut tracer une droite qui passe au milieu, chaque mouvement de règle change les betas. Pour savoir si la règle est bien placée :
- mesurer la distance entre les points et la règle (\(\varepsilon\))
- mettre ces distances au carré (les - deviennent +)
- On fait la somme
Le but est donc de minimiser cette quantité pour avoir la règle qui passe le plus près de tous les points.
Dérivée matricielle par rapport à \(\beta\)
Règles de dérivation : \(\frac{\partial(A'Z)}{\partial A} = \frac{\partial(Z'A)}{\partial A} = Z\)
où le ' désigne la transposée (on inverse les lignes et les colonnes de X).
Cette formule est un raccourci de la formule pour trouver \(\hat{\beta}\) qui consistait à « brute force » pour trouver les \(\beta\). Ici cette formule est compliquée et est toujours faite par un ordinateur.
\(X'X\) est inversible quand on a plus de données que de paramètres à estimer (\(n > p + 1\)). La matrice est en général inversible.
Propriétés
On veut que \(\hat{\beta}\) soit sans biais (en moyenne on ne se trompe pas) :
Plus la variance est faible, plus l'estimation sera précise.
Prédiction et résidus
Valeurs prédites
\(\hat{y}_i\) la prévision du modèle pour un ensemble de valeur. À partir de toutes ces valeurs on peut prédire \(\hat{y}_i\) à partir des coefficients qu'on a estimé.
Résidus
Écart entre l'observation et la prévision
Estimateur de la variabilité résiduelle
\(n - p - 1\) = nombre de données - nombre de paramètre à estimer à partir des données
\(\Rightarrow\) l'estimateur est sans biais
Décomposition de la variabilité
On va essayer de comprendre pourquoi les Y varient. Les Y sont les valeurs observées avec une certaine variabilité. On va chercher à comprendre cette variabilité et on va chercher à voir si notre modèle arrive à « comprendre » cette variabilité de Y.
| Source Variation | Somme des carrés | ddl (deg de lib) | Carré Moyen |
|---|---|---|---|
| Modèle | \(\sum_{i} (\hat{y}_i - \bar{y})^2\) | \(p\) | \(\frac{\text{SCM}}{p}\) |
| Résidu | \(\sum_{i} (y_i - \hat{y}_i)^2\) | \(n - p - 1\) | \(\frac{\text{SCR}}{n - p - 1}\) |
| Total | \(\sum_{i} (y_i - \bar{y})^2\) | \(n - 1\) |
Tableau d'analyse des variance.
Coefficient de détermination
Coefficient utile pour savoir si le modèle est bon ou non (R²). Pourcentage de variabilité expliqué par le modèle :
Plus R² est proche de 1, plus les prévisions du modèle sont proches des valeurs observées.
Propriétés :
- \(0 \leq R^2 \leq 1\)
- \(R^2 = 0 \Leftrightarrow \text{SCmodèle} = 0\)
- \(R^2 = 1 \Leftrightarrow \text{SCmodèle} = \text{SCtotal}\)
Inférence : test global
Pour vérifier si R² est significatif (si le modèle est intéressant), on va construire un test.
Hypothèses
H0 : le modèle n'est pas intéressant \(\Leftrightarrow R^2 = 0 \Leftrightarrow \beta_1 = \beta_2 = \ldots = \beta_p = 0\)
H1 : le modèle est intéressant \(\Leftrightarrow R^2 \neq 0 \Leftrightarrow \beta_1 \neq 0\) ou \(\beta_2 \neq 0\) ou ... ou \(\beta_p \neq 0\)
Sous H0
Si H0 est vrai :
Si ces 2 quantités sont comparables, alors on est sous H0
Principe du test : faire un test de comparaison de variance
Statistique de test
Loi de la statistique de test
Sous \(H_0\) : \(\mathcal{L}(F_{obs}) = \mathcal{F}_{p}^{n-p-1}\)
Décision
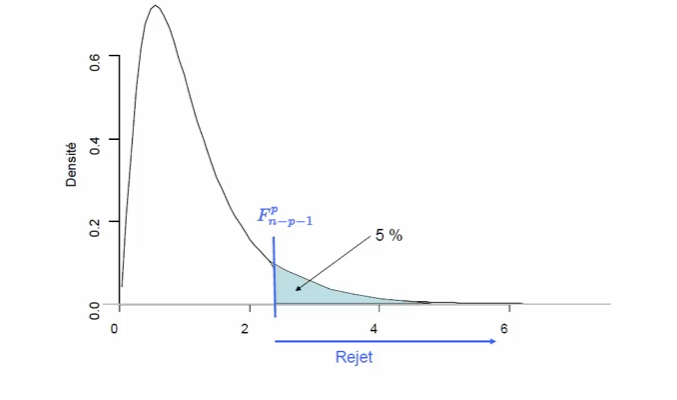
Si la statistique de test est très grande (par exemple 10), il y a peu de chance qu'elle suive une loi de Fisher, on remet donc en cause H0 qui suit une loi de Fisher. À contrario, si la valeur n'est pas très grande, par exemple 1, alors l'hypothèse est acceptable, on accepte donc H0.
Si le modèle n'est pas intéressant, c'est que les variables explicatives ne sont pas intéressantes.
Inférence : test d'un coefficient de régression
Loi de l'estimateur
Variable centrée réduite (cas où \(\sigma\) est connu)
Statistique de Student (cas où \(\sigma\) est estimé)
Exemple : Pour Beta1 sa loi est \(\mathcal{N} \left( \beta_1, \sigma_{\hat{\beta}_1}^2 \right)\)
Ensuite : on centre et on divise par l'écart type :
Comme on ne connaît pas la valeur de \(\sigma_{\hat{\beta}_1}\), on la remplace par son estimateur :
Grâce à cette loi, on peut construire des tests et des intervalles de confiance.
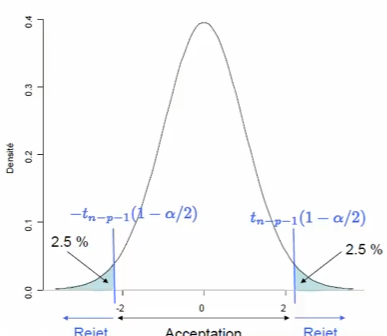
Hypothèses
\(H_0 : "\beta_j = 0"\) contre \(H_1 : "\beta_j \neq 0"\)
\(H_0\) : la variable \(j\) n'apporte pas d'information supplémentaire intéressante sachant que les autres variables sont déjà dans le modèle.
Statistique de test
Loi de la statistique de test sous \(H_0\)
Décision
Création du modèle
Etonnamment, la création du modèle était beaucoup plus simple que de comprendre le fonctionnement.
J'ai utilisé les bibliothèque numpy et pandas pour manipuler les matrices.
df = pd.read_csv("data.csv")
df["vitesse2"] = df["vitesse"]**2 #Car ici on sait que le temps de survie en fonction de la vitesse a une forme de cloche.
df["un"] = 1 # Colonne qui représente les Beta0 (temps de survie si tout les autres Betas sont à 0)
matrix_Y = df["time_lived"].to_numpy() #Matrice Y à prédire
matrix_X = df[["un", "resistance", "vitesse", "vitesse2", "satiete", "vision"]].to_numpy() #Matrice X, nos observations
# Beta_chapeau = (X'X^-1)X'Y
matric_X_transpose = matrix_X.transpose()
matrix_X_produit_transpose = np.dot(matric_X_transpose, matrix_X)
matrix_X_produit_transpose_invert = np.linalg.inv(matrix_X_produit_transpose)
matrix_X__before_final = np.dot(matrix_X_produit_transpose_invert, matric_X_transpose)
coef_beta = np.dot(matrix_X__before_final, matrix_Y) #Ici, on a donc les coefficients Beta. Il reste à vérifier si ils sont fiable
y_chapeau = np.dot(matrix_X, coef_beta) # Notre estimation des temps de survie
residus = y_chapeau - matrix_Y # L'erreur de notre modèle
estimateur_variabilite_residuelle = np.mean((matrix_Y - y_chapeau)**2) #Erreur total du modèle
estimateur_variabilite_naturel = np.mean((matrix_Y - np.mean(matrix_Y))**2) # Variabilité naturelle de la simulation (aléatoire)
coefficient_determination = 1 - estimateur_variabilite_residuelle/estimateur_variabilite_naturel # R², explique à quel point la matrice X impacte la matrice Y (est ce que les gènes sont important pour la survie)
variance_erreur = np.sum((matrix_Y - y_chapeau)**2)/(len(matrix_Y) - 6) #volume de hasard. Plus il est grand, plus c'est imprévisible
matrice_variance_covariance = matrix_X_produit_transpose_invert * variance_erreur #indique si les Beta risquent de changer si je relance une simulation
ecart_type_gene = np.sqrt(np.diag(matrice_variance_covariance)) #Marge d'erreur pour chaque gène. Plus il est gros pour chaque gène, moins il est solide
t_stat = coef_beta/ecart_type_gene #La solidité de nos estimations, plus ils sont haut, plus le Beta_chapeau est fiable.
Voici à quoi ressemble l'interface console
--- CONFIGURATION DE LA SIMULATION ---
Mode : [E]asy ou [A]dvanced ? e
Nombre de simulations [10] : 10
Nombre de Minos par simulation [50] : 100
Ratio de nourriture (ex: 0.5) [0.5] : 0.1
Configuration terminée. Lancement de la simulation...
simulation numéro 0 finie. time : 711.0
simulation numéro 1 finie. time : 743.0
simulation numéro 2 finie. time : 999.0
simulation numéro 3 finie. time : 655.0
simulation numéro 4 finie. time : 895.0
simulation numéro 5 finie. time : 615.0
simulation numéro 6 finie. time : 827.0
simulation numéro 7 finie. time : 778.0
simulation numéro 8 finie. time : 660.0
simulation numéro 9 finie. time : 749.0
lecture des données...
création des matrices...
calcul des coefficients...
calcul de l'estimateur...
calcul des résidus...
calcul de l'estimateur de variabilité résiduelle...
calcul de l'estimateur de variabilité naturel...
calcul R²...
calcul de la variance de l'erreur...
calcul matrice variance covariance...
calcul ecart type gènes...
calcul |T|...
--------Résultats----------
R² : 0.368099118877358
Dans la simulation, la génétique explique 36.810% de la survie d'un Minos, les 63.190 sont dues aux aléas de l'environnement.
|T| : [36.489 16.396 -0.807 4.659 4.89 15.184]
temps de vie de base 241.914 (36.489 de fiabilité)
La résistance a un impact positif de 59.926
la vitesse n'a pas de réel impact
La satiété a un impact positif de 18.959
La vision a un impact positif de 56.831